School of Data Science
Afgelopen week heb ik een uitstekende cursus van drie dagen gevolgd aan de School of Data Science (SDS). Een introductie over machine learning met een overzicht van de algoritmen die worden geschaard onder de categorieën supervised learning, unsupervised learning en reinforcement learning. Docent Farisch Hanoeman geeft op rustige en duidelijke wijze uitleg over de reikwijdte en de beperkingen van de toegepaste algoritmen. De hoofdbegrippen van machine learning worden toegelicht. De combinatie van theorie en praktijk, waarbij je in jupyter notebook opdrachten maakt in python code, is een prima manier om vertrouwd te raken met programmeren en van je fouten te leren. Ook leer je zo sneller handige trucjes met de vele libraries in python (pandas, numpy, sklearn, matplotlib). Deze cursus is een absolute aanrader als je geïnteresseerd bent in python en data science.
Wat is machine learning?
Er zijn meerdere definities, zoals bijvoorbeeld:
“Machine learning is het vakgebied waarbij computers bekwaamheid verkrijgen, zonder expliciet geprogrammeerd te worden.”
Een meer moderne definitie is als volgt:
“Een computer heeft geleerd van een ervaring E met betrekking tot een taak T gemeten in termen van een prestatie P, wanneer zijn prestaties in zijn taken, T, gemeten in P over het algemeen stijgt met meer ervaring, E.”
Neem het schaakspel als voorbeeld om de letters te duiden:
- E = de ervaring die je verkrijgt door het spelen van schaken.
- T = het schaken.
- P = de kans dat een programma wint met schaken.
De SDS maakt onderscheid in drie verschillende methoden van machine learning:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Supervised learning
Bij supervised learning is er sprake van de aanwezigheid van een dataset die gelabeld is met een correcte output. Wikipedia definieert supervised learning als volgt:
“… the task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples. In supervised learning, each example is a pair consisting of an input object (typically a vector) and a desired output value (also called the supervisory signal). A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples.”
Er zijn twee hoofdmethoden voor supervised learning:
- Bij continue waarden creëer je een functie op basis van regressie tussen input en output. Deze statistische methoden maakt gebruik van regressie techniek. De datapunten benaderd kunnen worden door een (lineaire) functie. Dat hoeft niet per se in de vorm van y = ax + b te zijn. Dit kan bijvoorbeeld ook een polynomiale functie of een ander type wiskundige functie zijn. Hoe kies je, bijvoorbeeld in het geval van een lineair verband, de parameters a en b? Je kiest deze waarden zo dat de afstand tussen de functie met gekozen parameters zo dicht mogelijk tegen de datapunten aan ligt. Ofwel: de Mean Squared Error die gelijk is aan de som van de gekwadrateerde fouten (tussen functie en datapunt) gedeeld door twee keer het aantal datapunten. De MSE geeft de zogenaamde cost functie weer: de laagste kosten vind je door de afgeleide van de functie aan nul gelijk te stellen. Een voorbeeld is de kalibratie van het weerstation P41_Ermelo op basis van lineaire regressie met de library sklearn. Met behulp van machine learning maakt het algoritme een keuze voor de beste ‘fit’ van een model, in dit geval een lineair model, die het verband geeft tussen de gemeten temperatuur van P41_Ermelo en een samengestelde temperatuur, afkomstig van de omliggende weerstations.
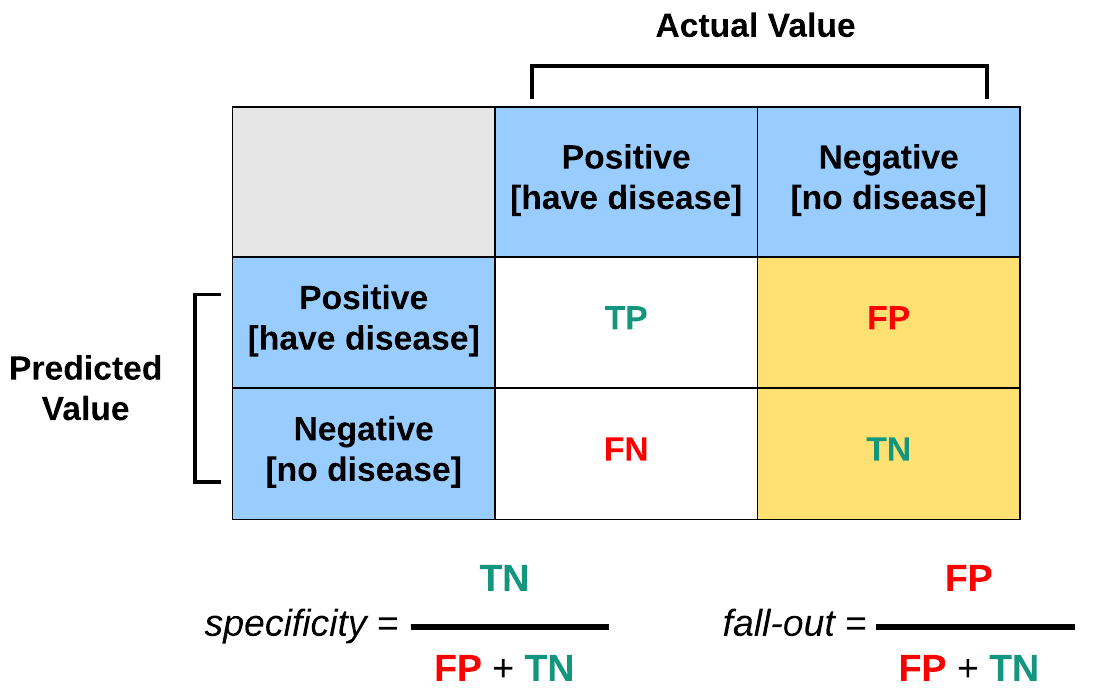
- Bij een classificatie probleem probeer je de input te categoriseren tussen input en output. Een voorbeeld van een classificatie algoritme is K-nearest neighbors (KNN). Voor dit algoritme is het nodig dat er al geclassificeerde data bestaat. Op basis van de geclassificeerde data kan nieuwe data geclassificeerd worden. In de cursus werd een classificatie toegepast op data van diabetes patiënten. In deze set was gegeven welke patiënten wel of niet diabetes hebben; er is dus een label beschikbaar om voor een nieuw datapunt (i.e. een mogelijke patiënt of niet) te labelen. Doel is om op basis van classificatie te voorspellen welke personen (in de dataset) diabetes hebben op basis van de gegeven data-variabelen zoals het suikergehalte in het bloed, de bloeddruk, het insuline gehalte, e.d. Uiteindelijk gaat het erom om de false negatives en false positives zo klein mogelijk te houden. De precision en recall waarden geven een indruk hoe accuraat en zinvol het algoritme presteert. Zie onderstaande formules.
Precision = True positive / # Predicted positives = True positive / (True positives + False positives)
Recall = True positive / # Actual positives = True positive / (True positives + False negatives)
Unsupervised learning
In de definitie van wikipedia is unsupervised learning als volgt omschreven:
Unsupervised learning (UL) is a type of algorithm that learns patterns from untagged data. The hope is that through mimicry, the machine is forced to build a compact internal representation of its world
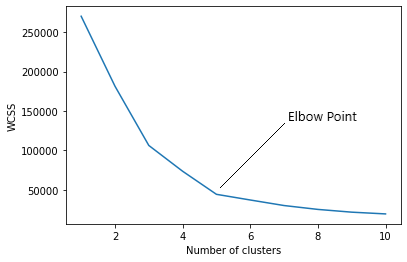
De SDS omschrijft het nog iets duidelijker: er is vooraf geen bepaalde relatie tussen input en output. Het gaat er bij unsupervised learning voornamelijk om om de structuur van de dataset te achterhalen. Deze structuur wordt gevonden door te kijken naar de onderlinge relatie van de datapunten. Voordat je aan de slag gaat met het toepassen van een algoritmen, kijk je eerst naar de data. Om hoeveel data gaat het? Wat zijn de variabelen? Hoe ziet de statistiek eruit (gemiddelde, mediaan, minimum, maximum, etc.)? Clustering is een van de meest gebruikte technieken voor data-analyse die wordt gebruikt om een gevoel te krijgen over de structuur van data. Met behulp van het K-means algoritme worden clusters bepaald op basis van onderlinge afstand van datapunten. Voor verschillende waarden van K (clusters) bepaal je vervolgens de mate van inertia per gekozen K-waarde. Hoe lager de inertie, hoe geringer de (gekwadrateerde) som van de datapunten tot het centrale punt per cluster. Echter dat wil niet zeggen dat je zoveel mogelijk clusters moet genereren. Meer clusters leidt weliswaar tot een lagere inertia, maar je wilt een optimum vinden. Teveel clusters is vergelijkbaar met een overfit polynomiaal model wat geen informatiewaarde meer heeft. Zoek dus het zogenaamde elleboog punt in de inertia-grafiek op: bij deze K waarde ligt het optimum aantal clusters.
Reinforcement learning
Reinforcement learning (RL) is het vakgebied binnen machine learning waar acties door een systeem genomen worden om een bepaalde beloning te maximaliseren. Er zijn geen vooraf gedefinieerde gelabelde data aanwezig die aangeven of het algoritme iets correct gedaan heeft. Een voorbeeld is het vinden van een pad uit een doolhof, een zelfrijdende auto of het spelen van een schaakspel (en hierin steeds beter worden). Door te sturen op maximaal onderscheidend vermogen per vraag (per ‘tak’ van de boom) is het doel om een zo eenvoudig mogelijke decision tree te verkrijgen. Maar eerst is de vraag hoe je überhaupt een boom kunt creëren met data uit een tabel. Welke kenmerk (feature) vormt de root node van de boom? En op welke basis kan deze node gesplitst worden in een internal node of een leaf node?
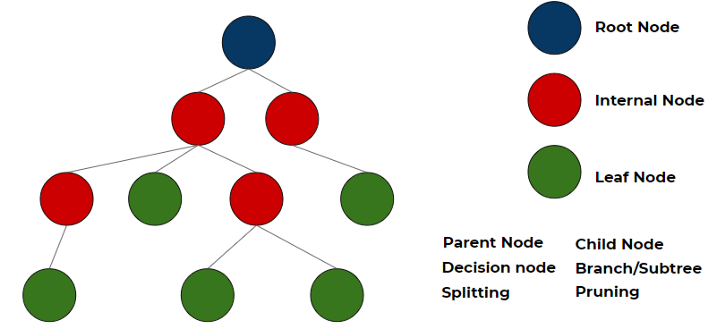
De keuze welke splitsingen in de boom moeten worden opgenomen en in welke aantallen, beïnvloedt de nauwkeurigheid van de beslisboom. De zogenaamde puurheid van de node is een waardevolle metriek om de informatiewaarde van de boom te vergroten. De puurheid van de node verbetert naarmate je dieper in de boom geraakt. Het algoritme splitst de nodes op basis van alle beschikbare variabelen en selecteert dan die nodes die de meest informatieve waarden geven. De kwaliteit van de splitsing, de informatiewaarde, kun je kwantificeren met de Gini impurity waarde.
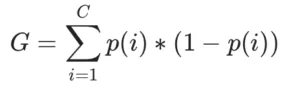
Bias en variance
Een van de problemen bij machine learning algoritmes, is het bias & variance probleem. Kies je een té eenvoudige functie om de datapunten te modelleren, dan is er sprake van een bias. Het maakt niet uit hoe je de parameters van de functie ook kiest, het model zal altijd een inherente fout in zich hebben. Het model heeft een hoge bias. Wanneer je de afstanden optelt van de datapunten tot het model, de Mean Square Error, bereken je de maat voor de fout van het model. Je kunt in het andere uiterste kiezen voor een model dat perfect de datapunten kruist zoals bijvoorbeeld met een ingewikkelde polynomiale functie. Het model gaat perfect door alle modeldata (training data) heen maar op de testdata is de fout (tussen model en testset) heel groot. In dit geval is er sprake van een hoge variance: het model is overfit. In het ideale geval wil je een model dat zowel een lage variance heeft als een lage bias. Zoals de SDS zegt: de middenweg tussen een simpel model en een complex model.
Deze driedaagse data science cursus van SDS heeft me veel opgeleverd en inspireert tot het verder verfraaien van de maandoverzichten van het weer, het uitvoeren van kalibratie van de temperatuurwaarnemingen en nog meer zaken op het gebied van algoritmen en python.